Prometheus(프로메테우스) + Grafana(그라파나)로 모니터링하기
Prometheus(프로메테우스) 란?
오픈 소스 기반의 모니터링 시스템이다. 대상 시스템으로 부터 각종 모니터링 지표를 수집하여 저장하고 검색할 수 있는 시스템이다. 구조가 간단하여 운영이 쉽고, 강력한 쿼리 기능을 가지고 있다. 또, 그라파나를 통한 시각화를 지원한다. 무엇보다 넓은 오픈 소스 생태계를 기반으로 해서 많은 시스템을 모니터링할 수 있는 다양한 플로그인을 가지고 있다. 특히, 이런 간편함 때문에 쿠버네티스의 메인 모니터링 시스템으로 많이 사용되면서 요즘 특히 더 주목을 받고 있다.
✅ SoundCloud사에서 만든 오픈 소스 기반 모니터링 솔루션
✅ go언어로 만들어짐
- 하드웨어 레벨 / 애플리케이션 모니터링 가능
- 마이크로서비스
- multiple language 지원(java, go 등)
- window / linux
✅ PULL 방식 아키텍쳐
- tcp / udp 오버헤드가 적음
- 집계가 PUSH보다 쉬움
- 부하가 높은 상황에서는 fail point를 비교적 예방 할 수 있음
- 하지만, 수집 메트릭과 룰이 많아질 수록 configuration이 복잡해짐
- 단일 노드 동작으로 스케일 아웃(장비추가)이 어려움
📌 PUSH 방식?
- 패킷손실, 수집처 서버의 CPU 사용율, 단일 장애의 위험성이 있음
✅ 메트릭 수집, 시계열 DB(TSDB) 사용
- 수집된 메트릭은 용량을 압축하여 저장하고 시계열 데이터베이스의 뛰어난 성능을 기반으로 많은 메트릭을 빠르게 조회 할 수 있다.
📌 메트릭이란?
- 시스템 상태를 알 수 있는 특정 값
- CPU, 메모리 사용량 / HTTP 상태표 등과 같은 값을 알 수 있음
✅ PromQ1 이라는 쉽고 간결한 자체 쿼리 언어 지원
- 사용자가 실시간으로 시계열 데이터를 선택하고 집계할 수 있음
프로메테우스 구조

✅ Prometheus server
- 수집된 메트릭을 PULL 방식으로 가져와 TSDB에 저장
- 외부 노출을 위한 HTTP 서버 존재
✅ Node-Exporter
- 하드웨어의 상태와 커널 관련 메트릭을 수집하는 메트릭 수집기
- 각 노드에 Linux 레벨의 메트릭을 수집
- metrics HTTP endpoint에 접근하여 해당 메트릭을 수집할 수 있음
- Node Exporter로 부터 수집한 메트릭을 Prometheus 내의 TSDB에 저장하여 PromQL로 메트릭을 쿼리해 서버 상태를 모니터링
✅ Kube-state-metrics
- 클리스터의 여러 메트릭 데이터를 수집
- 수집 된 데이터를 프로메테우스가 수집할 수 있는 메트릭 형태로 반환 후 공개
✅ AlertManager
- Alet Rule을 설정하고, Event 발생 시 설정된 Alert 메세지를 전달
- Email Slack, Webhook 등의 방법으로 전달
- Grouping
- 유사한 성격의 정보를 하나의 알람으로 분류
- 알람이 많이 발생하는 경우 사용하면 좋음
- 대규모 이벤트가 발생했을 경우 직관적으로 확인하기 어렵기 때문에 해당 기능을 사용 - Inhibition
- 특정 경고가 활성화 되어 있을 경우, 타 경고 알람을 억제하는 역할 - Sliences
- 주어진 시간동안 발생하는 경고를 음소거 하는 역할
- 경고에 대한 알람이 발생하지 않음
데이터를 수집하는 방식
- Node-exporter
- exporter는 수집한 메트릭을 HTTP를 통해 가져갈 수 있도록 /metrics 라는 HTTP endpoint를 노출
- CPU, Memory, disk, network 등 노드에 대한 메트릭 수집
- Retrieval(리트라이버)
- 수집 대상에서 메트릭을 가져오는 역할
- TSDB
- 시간을 기준으로 저장(Key:Value 형태로 저장)
- 전반적으로 뛰어난 성능 보유
- HTTP Server
- 프로메테우스에 저장된 데이터를 조회하는 역할
- HTTP REST API를 제공
- 대시보드 구성 지원
프로메테우스 설치 ( Ubuntu ) + Docker
📚 공식 문서
https://prometheus.io/docs/prometheus/latest/installation/
Installation | Prometheus
An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
prometheus.io
1. local(host)에 prometheus.yml 생성
sudo vim /[경로]/prometheus.yml- Docker가 실행 될 때 host의 prometheus.yml 파일을 마운트 시켜서 설정 파일로 사용
global:
scrape_interval: 15s
evaluation_interval: 15s- scrape_interval (default : 1분)
- 메트릭을 수집할 주기
- evaluation_interval (default : 1분)
- alert에 대한 rule을 평가하는 주기
2. Docker run 명령어를 사용하여 컨테이너 띄우기 + 마운트
- docker 컨테이너로 프로메테우스를 띄우기 때문에 컨테이너가 내려가면 저장된 데이터들도 모두 지워진다.
👉 마운트를 사용하여 데이터가 유지될 수 있도록 한다.
sudo docker run \
-p 9090:9090 \
-v /[경로]/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus- -p : 9090
- -v 옵션을 사용하여 바이트 마운트
- prom/prometheus → 최신 이미지를 pull 받아 컨테이너를 생성함
3. Spring Boot Actuator를 사용하여 메트릭 가져오기
- 보통 exporter 수집기를 사용하여 가져오는데 Spring Boot 에서 제공하는 Actuator를 사용하여 가져 올 수도 있다.
- Spring Boot Actuator는 스프링부트의 서브 프로젝트
- Spring Boot Actuator를 활성화하면 애플리케이션을 모니터링하고 관리할 수 있는 엔드포인트에 접속이 가능해진다.
- 의존성 추가
implementation 'org.springframework.boot:spring-boot-starter-actuator'
runtimeOnly 'io.micrometer:micrometer-registry-prometheus'- 기본적으로 제공하는 엔드포인트 목록 보기
- http://{project 주소}/actuator

- application.yml 에 prometheus에서 사용되는 메트릭에 대한 엔드포인트를 노출 시키기 위해 아래와 같은 설정 추가
management:
endpoints:
web:
exposure:
include: prometheus- include : 노출할 엔드포인트 이름을 쉼표로 구분하여 기입
- exclude : 노출하고 싶지 않을 때

- 다시 조회해보면 위와 같이 추가된 것을 확인할 수 있음
4. prometheus.yml 파일 수정
global:
scrape_interval: 15s
evaluation_interval: 15s
# Alertmanager 설정
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# 규칙을 처음 한번 로딩하고 'evaluation_interval'설정에 따라 정기적으로 규칙을 평가한다.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs:
- job_name: [작업 이름]
static_configs:
- targets: ["<springboot-app-host>:<springboot-app-port>"]Grafana(그라파나) 설치 및 대시보드 추가 + Docker
- 그라파나는 프로메테우스의 그래프나 추이를 시각화하여 볼 수 있음
docker run --name grafana -d -p 3000:3000 grafana/grafana- 기본 접속 정보 admin / admin
- 기본 PORT : 3000
1. 그라파나에서 프로메테우스의 데이터를 가져오기 위해 Datasource가 추가되어야함
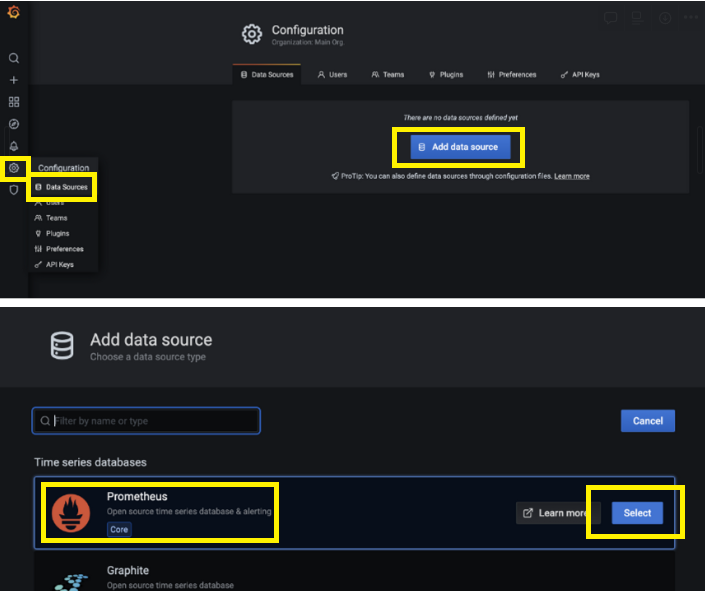
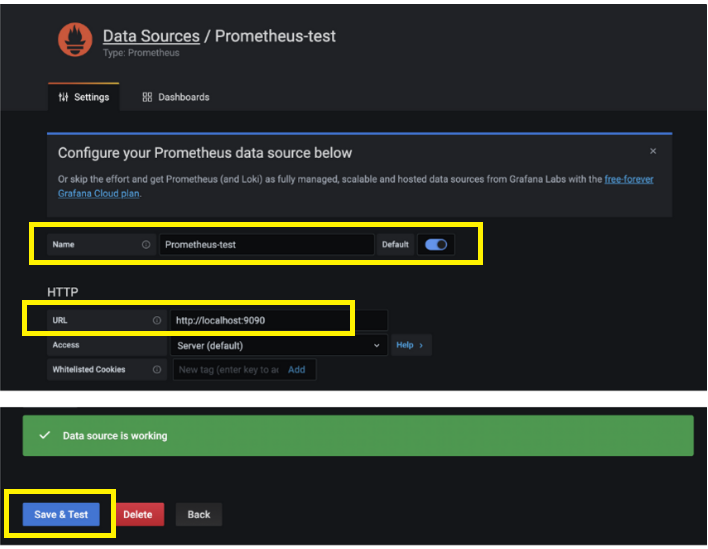
📚 참고 자료
Prometheus - Monitoring system & time series database
An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
prometheus.io
오픈소스 모니터링툴 - Prometheus #1 기본 개념과 구조
프로메테우스 #1 기본 개념과 구조조대협 (http://bcho.tistory.com) 프로메테우스는 오픈 소스 기반의 모니터링 시스템이다. ELK 와 같은 로깅이 아니라, 대상 시스템으로 부터 각종 모니터링 지표를 수
bcho.tistory.com